Redis 详解
数据结构
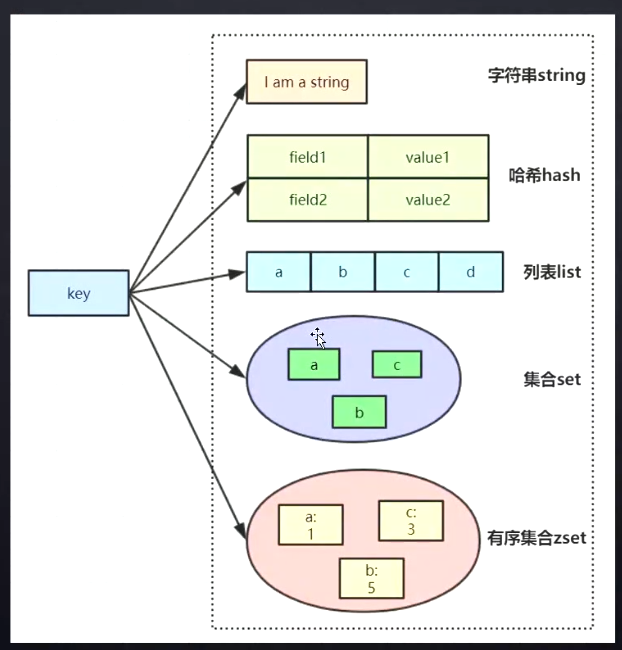
String 应用场景
单值对象
对象缓存
1. 可以直接 SET 对象,将对象序列化,存储 json 对象
2. 可以 MSET 对象,将所有属性单独序列化,便于频繁修改对象属性值(只用修改这一个值)
分布式锁
1 | SETNX product:10001 true // 返回 1 是取锁成功 0 是失败 |
计数器
1 | INCR ariticle:readCount:{ 文章 id} |
Web 集群 session 共享
spring session + Redis 实现共享
分布式系统全局序列号
1 | iNCRBY orderId 1000 // Redis 批量生成序列号 |
哈希 Hash 应用场景
对象缓存
1 | HMSET user {userId}:name dd {userId}:balance 555 // 即将对象属性拆分为一个 map 集合 大对象存储需要用分段存储 |
电商购物车
以用户 Id 为 key,商品 id 为 field,商品数量为 value
1 | hset cart:1001 55 1 // 添加商品 |
优缺点
优点
- 同类数据归类整合存储,方便管理
- 比 stirng 消耗内存与 cpu 更小
- 比 string 更节省空间
缺点
- 过期功能只能用在 key 上,不能用于 field 上
- Redis 集群下不适合大规模使用(容易集中到一个机子上)
列表 list 应用场景
常用命令

常用数据结构
Stack(栈) = LPUSH + LPOP =FILO
Queue(队列) = LPUSH + RPOP
Blocking MQ(阻塞队列) = LPUSH + BRPOP
微博和微信公众号消息流
如发消息,使用队列,然后用 LRANGE 拿出来
微博小 V 使用 push 大 V 使用 pull
- push 是小 V 放入 Redis 中,用户拿自己消息队列中的消息
- pull 是用户去拿大 V 发过的消息排列
Set 应用场景
微信抽奖小程序
1 | // 1. 参与抽奖 |
微信微博点赞,收藏,标签
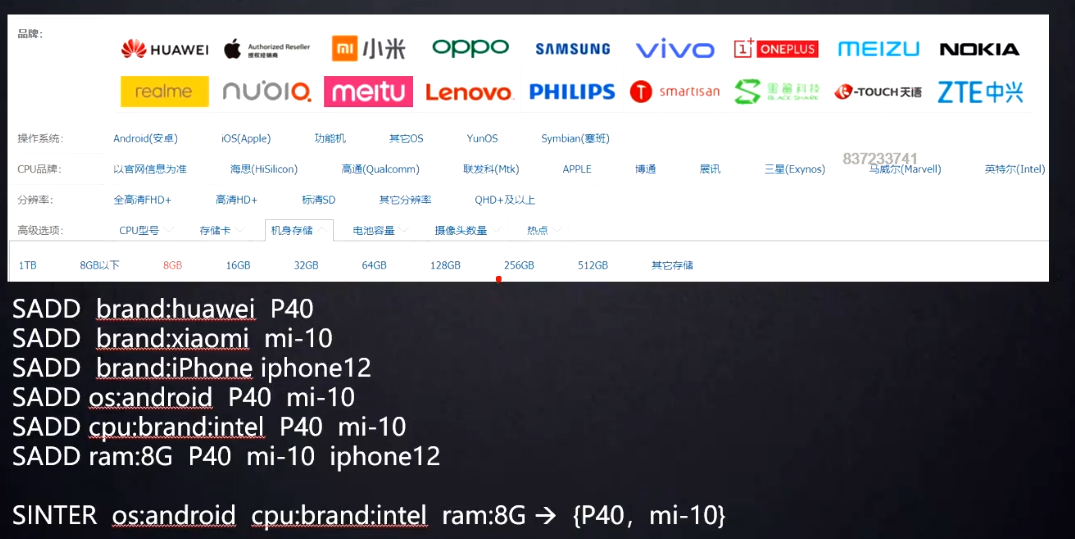
1 | SADD like:{ 消息 ID} { 用户 ID} // 点赞 |
集合操作
1 | SINTER set1 set2 set3 // 获取交集 |
微博微信关注模型
1 | AAset -> {CC, DD} // AA 关注人 |
电商商品筛选
Zset 集合应用场景
排行榜
1 | ZINCRBY hotNews:20190819 1 // 点击新闻 |
Redis 的单线程和高性能
Redis 是单线程吗
主要是指网络 IO 和键值对读写是单线程,但是其他功能,如持久化、异步删除、集群数据同步是额外线程执行
Redis 为什么单线程还快?
所有数据都在内存中
Redis 单线程如何处理并发客户端连接?
IO 多路复用 (NIO),使用 epoll 实现的,将连接信息和事件放入队列中,依次放到文件事件分派器,分派器再将事件分发给事件处理器
默认最大连接数 1w
Redis 如何做分页
1 | scan cursor [MATCH pattern] [COUNT count] // cursor 游标,即查询起点 |
Redis 底层数据结构简析
类似于 HashMap ,一个数组下的键值对的链表,cursor 即数组的位置,因为没有并发涉及,查询时插入会导致数据有误
Redis 持久化
RDB、AOF 及混合持久化
RDB 快照
1 | save 60 10000 // 同步保存 每 60 秒内有 10000 次操作,将其保存至.rdb 文件 |
如果故障,服务器会丢失最近写入、未保存到快照中的数据
AOF 持久化
将 ** 修改 ** 的每一条指令记录文件 appendonly.aof 文件中(先写入 os cache,再隔一段时间 fsync 到磁盘)
1 | appendonly yes // 开启持久化 |
AOF 重写
定期根据内存最新数据生成 aof 文件
1 | auto-aof-rewrite-percentage 100 // 自上次重写后增长 100% 再次触发重新 |
重写也会 fork 一个子进程去做
AOF 与 RDB 比较
| 命令 | RDB | AOF |
|---|---|---|
| 启动优先级 | 低 | 高 |
| 体积 | 小 | 大 |
| 恢复速度 | 快 | 慢 |
| 数据安全性 | 容易丢数据 | 根据策略决定 |
混合持久化
1 | aof-use-rdb-preamble yes |
将每次 ** 重写 ** 时,将之前的内存做 RDB 快照处理,并将快照内容和 ** 增量 **AOF 修改命令存在一起,等重写完后再将名字改为
appendonly.aof,将原有文件覆盖
Redis 备份策略
- 写 crontab 定时调度脚本,每小时 copy 一份 rdb 或 aof 备份到目录中,仅保存最近 48 小时的备份
- 每天保留一份当日数据
- 每次 copy 备份时,把太久的删除
- 每晚当前机器备份复制到其他机器上
Redis 主从配置
配置步骤
复制 Redis.conf 文件
将相关配置修改
1
2
3
4port 6380
pidfile /var/run/Redis_6380.pid # 把 pid 写进 pidfile 配置文件中
logfile "6380.log"
dir /usr/local/Redis5.0.3/data/6380 # 指定数据存放目录配置主从复制
1
2replicaof 192.168.0.60 6379 # 从本机 6379 的 Redis 实例复制数据
replica-read-only yes # 配置只读启动从节点
1
Redis-server Redis.conf
连接从节点
1
Redis-cli -p 6380