Dubbo 底层原理
引用与导出
消费者引入,服务者导出
导出
3.0 版本之前
- 识别 @DubboService 注解
- 寻找 ServiceConfig
- 调用 export() 方法
- 确定使用协议
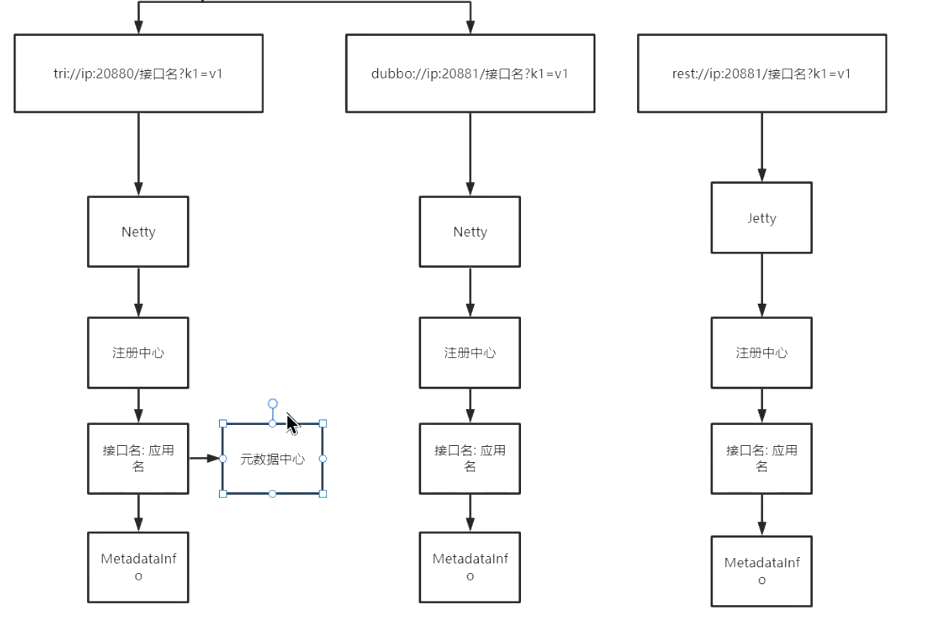
- 生成对应的 url(tri://ip:port/ 接口名?k1=v1)
- 启动对应通信框架
- 注册到注册中心
3.0 版本之后
- 保存的为应用,但是接口也会默认保存,以兼容老版本消费者,可修改配置更改策略
- 在 zookeeper 存放位置与 cloud 一致
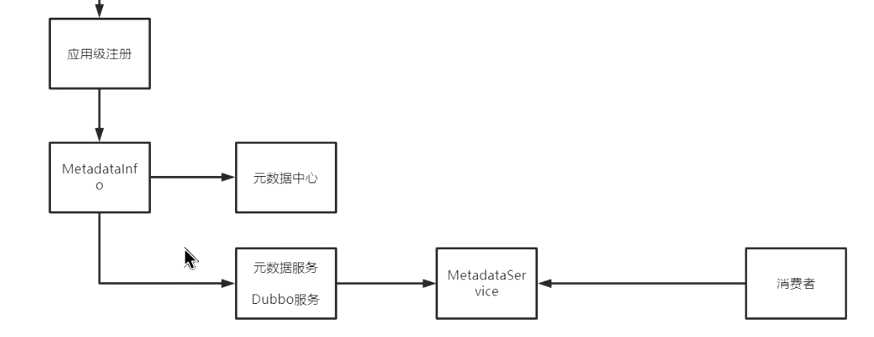
- 注册接口名:应用名,保存到元数据中心(可配置,放在 Redis 或者 zookeeper 上)
- 解构保存到 MetadataInfo 中
- 保存的到元数据中心,或者保存到元数据服务中( dubbo 自带服务,使用的为 dubbo 协议,MetadataService,消费者也可以直接调用这个服务)
- 最后保存为
应用名:ip+ 端口
1 | ## 提供者 |
引入
3.0 之前(接口级)
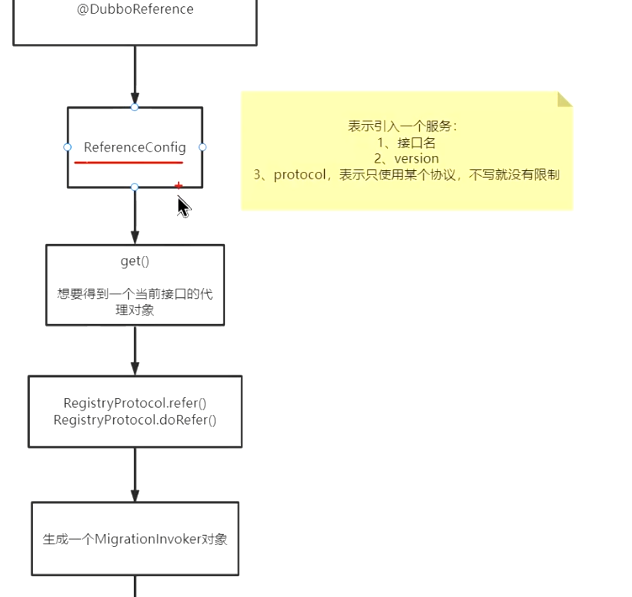
- 注解映入 dubbo 服务
- 通过引入配置来选定引入的具体某个接口
- 配置接口后通过 get() 获取接口代理类
- 通过注册协议去查询
- 生成 migrationInveoker 代理对象
- 通过 migration.step 配置选择使用什么方式查询服务
- 查询注册中心服务后,找到所有的服务 url
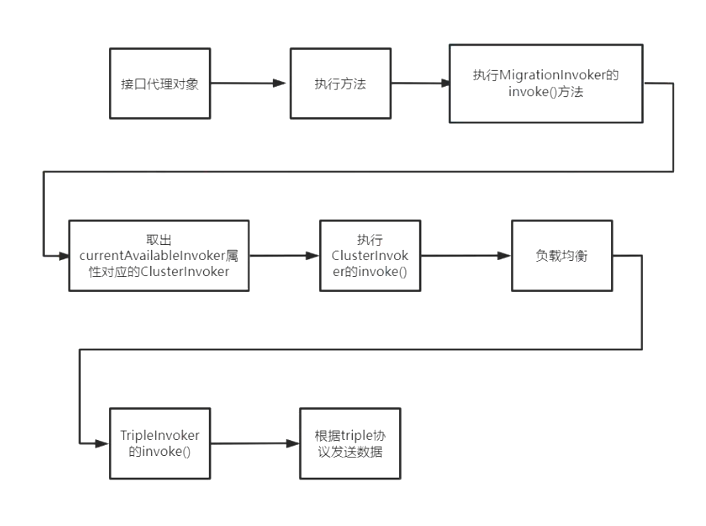
- 生成不同协议的 Invoker,最后统一使用 ClusterInvoker
- 生成对应的代理对象,执行代理逻辑,执行使用 ClusterInvoker 的 invoke 方法
- 最后负载均衡使用具体某个协议的 Invoker 的 invoke 方法
3.0 之后(应用级)
- 先去元数据中心,通过接口名查询对应的应用名
- 通过应用名去找到所有实例信息
- 通过信息提供方式去查询(元数据中心或者元数据服务)
- 通过元数据信息去找到所有服务 url(所有应用的服务 url 都会在这里一起查询到)
- 缓存服务 url,通过接口和协议过滤,如同一应用的新接口过来,就可以直接过滤
- 生成不同协议的 Invoker,最后统一使用 ClusterInvoker
- 赋值给 MigrationInvoker 的 invoker 和 currentAvilvbleInvoker 属性
- 基于 MigrationInvoker 对象获取代理对象
1 | ## 消费者 |
应用优先
8 或 12. 应用和接口都会生成对应 ClusterInvoker
- 赋值给 MigrationInvoker 的 invoker 和 currentAvilvbleInvoker 属性
- 如果只有一个,就用那一个
- 如果两个都有,则使用配置
migration.threshol来判断使用哪一种 ,默认migration.threshol为 0,即默认使用应用级 - 基于 MigrationInvoker 对象获取代理对象
MigrationInvoker 执行逻辑
使用 MigrationInvoker 主要是为了使用参数配置有两种 ClusterInvoker 时的优先级
grpc 互通和 cloud 互通
grpc 互通
必须使用 triple 协议
dubbo 调用 grpc 服务
即消费者端配置
1 | // 指定 url,grpc 不用注册中心,直接直连 |
grpc 调用 dubbo 服务
也是通过 url 直连 dubbo 对应接口
cloud 互通
dubbo 调用 cloud 服务
cloud 直接注册到注册中心,cloud 走的为 http 协议,只能使用 rest 协议
1 | // 公共接口类上接口需要配置对应 rest 地址 |
cloud 调用 dubbo 服务
1 |
|
细节点
元数据中心和注册中心的区别
3.0 前为了缓解注册中心压力,将服务中与消费者无太大关联的信息(参数)放入元数据中心中
3.0 后直接用于保存应用中注册的接口服务,这是 dubbo 内部服务
消费者流程

endpoints: 保存的使用协议和对应端口号
个人理解的 dubbo 流程是消费者去中间服务器获取服务类的信息,dubbo 会根据注册的类信息生成不同代理类,由统一的代理类处理消费者访问,只是访问前会通过策略选择具体的某一个代理类执行,数据通信的还是消费者和提供者,中间服务器只是作为一个提供者注册和消费者查询的作用
2
// 选择使用哪一个协议,没写则默认是每一种协议都生成
元数据更新
消费者监听 zookeeper 中的数据是否变化,如果变化了,则消费者会更新服务缓存
dubbo 协议
默认三种,dubbo,rest,triple,在注册应用级服务时,默认使用 dubbo 协议的端口,如果无 dubbo 协议,且未配置元数据服务,则获取 URLs 中第一个协议端口号,若配置了元数据服务(使用的是 dubbo 协议),则默认端口 20880,如果被占用则自旋 +1
同一协议不同端口的 bug
dubbo 协议
存入 endpoints 中时,使用的是以协议为 key 的 map,所以使用 dubbo 协议不同端口号时,会被覆盖掉。所以在消费者生成对应的代理类时,只会生成其中一个(因为通过 endpoint 来查询的对应 url),这种 bug 只会在应用级服务时生成,接口级服务直接查找到对应服务,不需要查询 endpoints
triple 协议
服务导出时,提供者会进行本地注册,会通过具体的实例对象、服务 URL、接口 class 对象来实现一个 Invoker,消费者代理类过来,查询 map 来调用这个 Invoker 执行实例对象中具体的方法。
所以在同一协议不同服务 url(端口号不同)时,会生成两个 Invoker。
而在这个步骤中,查询的 map 中的 key 为接口名,所以在赋值 map 时,Invoker 也会发生覆盖,实际执行的永远只有一个。
但 dubbo 中会将端口号存入其中,所以没有这个问题
服务调用原理
Http2
设计了帧的概念,通过帧长度可以知道,一次请求最大数据量为 16M(2^24^),其中会有 header 帧和 data 帧

Http2 与 Http1 的区别
http1 通过空格和换行符来判断信息类型,http2 只有请求头和请求体,且已经标明大小,则如只要请求体,则直接从第 10 个字节后开始取
http2 会对请求头进行压缩
http1 在同一 socket 连续发送两个请求,服务器同时处理后,无法区分请求结果对应的哪一次的请求,所以现在设计为一次请求就对应一次响应(request-response 模型),浏览器在同一域名下一般最多创建 6 个 socket 连接,所以在页面下异步请求最多也就只支持 6 个。
http2 可以
用标志位来标记是否传输完成,如将标志位中设置一参数为 0,流标识符 (StreamID) 为请求 id,则可以同一请求发多次帧进行传输,直到标志位为 1 时,请求才算结束
通过流标识符来区分多个请求,这样就可以在一个 socket(基于 TCP)中连续发送多次请求
http2 创建流程
- 创建 socket 连接后,就会发送一个连接前言,告诉服务端发送到是 http2 协议
- 生成 StreamID 向服务器发送控制帧,从而在服务器中生成对应的几个 StreamID
- 后续发送请求则代入 StreamID,服务器通过 ID 组装
- 直到发送 end 标识,服务器组装完毕,构造一个完整的请求