线程基础
Callable 实现原理
Callable 接口按照 Runnable 方式写作一个可带返回参数的接口,即 call() 参照 run()。
其中有两点需要考虑:
- 有返参,但主线程如何从线程中获取返参
- Thread 执行方法中,只有 Runnable 类型 参数
所以此时:
- 构建一个 Future 接口,其中 get()方法是用于获取 call() 方法结果
- 构建一个 RunableFuture 接口,继承 Runnable 和 Future
这样,实现了 RunnableFuture 接口的实现类 FutureTask 可以解决以上问题
具体为:
- FutureTask 中 Callable 属性赋值
- 重写 run()方法,其中调用 callable 的 call() 方法获取到返回值,将返回值调用 set()方法赋值给 outcome 属性,同时将 state(
即线程状态属性) 赋值为 normal - 然后 futureTask 调用 get() 方法去拿取 outcome 的值,因为是异步的,此时需要判断 state 属性判断线程是否执行完成
- 如果没有执行完,则通过 awaitDone() 方法循环等待,可以设置超时时间,如果超时则报错,如果未设置,则一直循环获取
- 其中有一个 WaitNode 内部类,获取当前线程状态,从而循环判断 state 的值
创建线程方式
Thread 源码上写的就两种
- 继承 Thread 类
- 实现 Runnable 接口
future 本质也是实现了 runnable 接口,在 run 方法中调用了 callback 的 call() 方法
start 方法
实际是调用了 start0() 本地方法,同时调用本地方法前会有检查,如执行两次 start 方法,会抛出异常
Thread 对象实则只是堆对象,真正调用线程是通过 Thread 的 start 方法去调用 start0()本地方法调用的,而 run() 方法对于线程类似于主线程的
main() 方法,让线程知道需要执行该方法。
线程终止方式
自然死亡
run() 跑完
抛出未捕捉异常
自定义死亡
使用 stop()
已弃用,不能确定线程状态,直接停止,线程可能没有跑完就停了
中断
A 调用 B 的 interrupt()方法,设置 B 的中断标记位为 true,B 是否终止由 B 线程自行决定,B 通过 isInterrupted()
来获取中断标志位,程序员可以在程序中自行编写结束代码不建议自定义中断标志位,因为线程如果有阻塞调用,线程不会获取到 cpu 资源,无法执行对应赋值方法,即线程无法第一时获取到自定义的中断标志位
而 interrupt 调用时,线程阻塞方法自带了中断标志的检查,即修改中断标志位后,线程也会自己被唤醒,从而能执行中断方法
线程的生命状态
初始 - 运行中 - 就绪 - 阻塞 - 超时等待 - 等待 - 终止
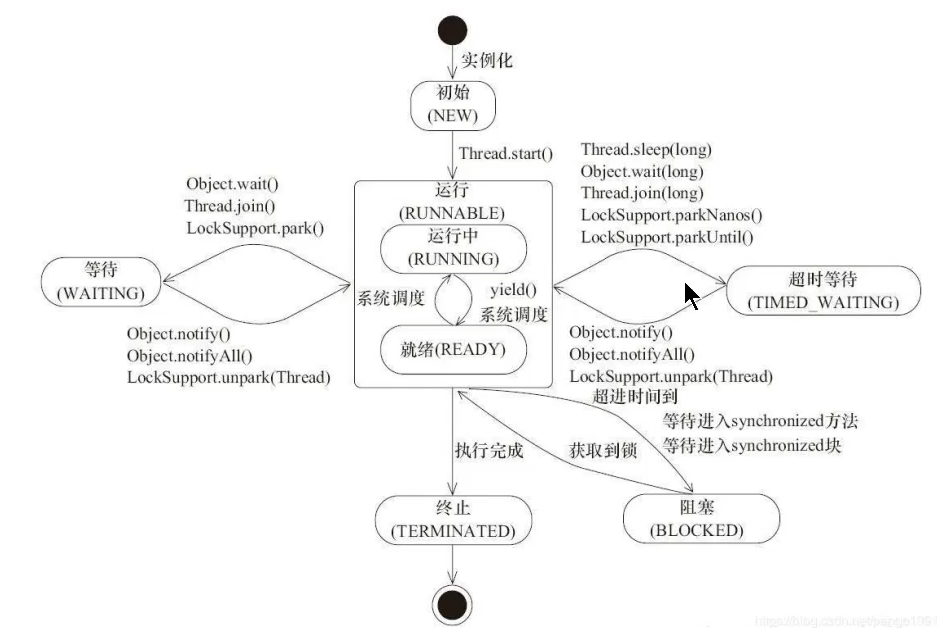
阻塞
只有被 关键字才会阻塞
yield 实例
在 ConcurrentHashMap 初始化时,会调用 yield() 方法
原因是在 ConcurrentHashMap 在初始化时没有生成数组,而是在 put 时才会生成数组,在多个线程调用 put
时,为了让数组最快生成,则让一个线程生成,其他线程让出 cpu 资源。
线程的调度
协同式调度
线程自己控制,如果阻塞可能就一直阻塞,无法让给其他线程
抢占式调度
系统控制,线程执行时间不可控,阻塞后,其他线程可以抢占 cpu 资源
java 是抢占式调度,通过 ** 线程优先级 **,在就绪状态时,优先级越高的线程越容易执行
线程实现
内核实现
语言启动,则硬件线程和操作系统是 1:1 实现,cpu 一个线程对应一个操作系统线程
用户实现
操作系统实现逻辑线程,可以让硬件线程和操作系统作为 1:N,一个 cpu 对应操作系统的多个逻辑线程
golang 对应
混合实现
即实现多个逻辑线程同时,可以对应多个硬件线程,即 M:N
协程
适用于 IO 密集型(高并发),计算密集型反而会降速
有栈协程
无栈协程
java 的协程——Quasar
1 | <!-- 引入 --> |
1 | // 使用 |
守护线程
支持工作,如 GC 等
1 | UserThread userThread=new UserThread();// 死循环 |
线程间通信
管道的输入输出流
案例:** 数据库 ** 统计 ** 报表 ** 生成 **excel 文件 ** 上传给 ** 远端 **,
使用管道则可以不用在本地生成 excel 文件,直接上传给远端
具体实现为
1 | // PipedOutputStream 和 PipedInputStream(字节)、PipedReader 和 PipedWriter(字符) |
join()
保证三个线程依次跑完,可以用 join() 方法
synchronized 内置锁
强制将并行变为串行,只能传入对象实例
1 | // 对象锁 |
1.8 之后引入了轻量级偏向锁,如果竞争少的情况下会 cas 自旋拿锁
对象锁和类锁
对象锁:用于对象实例,或者对象实例方法
类锁:写在静态方法,或者类的 class 对象上
1 | // 想要锁生效,两线程调用的锁对象必须是同一对象 |
volatile
保证了不同线程对变量操作的可见性,线程修改后立即可见
适用场景:一个线程写,多个线程读
不是锁,无法保证串行
等待 / 通知机制
wait() 未设置超时时间,设置线程为等待
wait(Long time) 设置超时时间,设置线程为超时等待
等待和通知范式
1 | 等待方: |
1 | // 实际案例 |
面试题
方法和锁
yield()、sleep() 线程方法,不会释放锁
wait(),notify() 对象方法,wait()会释放锁,notify() 通知作用,对锁无影响
为什么 wait()和 notify() 需要在同步块里调用
如果不这么设计,会导致 LostWeakUp, 丢失唤醒信号。
即不在同步块时,A 可能会在 B 执行 notify()之后再 wait(),这样就会丢失 B 的 notify() 信号,从而一直 wait。
同步块则保证了 A 执行了 wait()方法之后释放了锁,B 才能执行 notify() 通知方法
为什么要循环中检查等待条件
因为多线程 wait()时,当 notifyAll() 通知所有线程后,多个线程不一定就都能满足条件,如果不满足,则还需要进入等待状态
比如生产者生产一条消息被多个消费者竞争,始终只有一个消费者线程抢占到锁拿到该消息,抢占到消息 (即抢占到锁) 的消费者线程执行完后则释放锁让其他线程执行,其他未抢占到消息的线程抢到锁执行后,则仍然继续等待,所以不代表唤醒后就一定能执行,每次唤醒后还需要重新判断是否抢占到资源,如果没有,则还需要执行等待方法
CompletableFuture
future 的缺点
- 调用 get() 方法会一直阻塞直到计算完成,没有提供完成通知的方法,也不具有回调函数的方法
- 链式调用和结果聚合处理时,需要调用的多个 future 进行处理,
- 没有提供异常处理方法
CompletableFuture 针对以上痛点都有自己的设计